Trick of the trade - text similarity: TF-IDF vs spaCy

Artificial intelligence has been a fascinating subject to all of us. Every business and technology leader, has exciting ideas on using natural language like conversations for interaction in their business.
One of the most essential feature of natural language processing is to determine the intent of the person our machine is interacting with. The challenge here is that same intent can be conveyed in very different ways.
How do we yet manage to provide a correct response in every case?
What is text similarity ?
In context of textual information, text similarity can be looked at in two ways:
a) Syntactic Similarity b) Semantic Similarity
While syntactic similarity of text have very limited utility, semantic similarity can play a big role in text processing like for intent classification, automated evaluation of answers to a specific question by user etc.
Current Scenario
Although jargons are something we all want to avoid, let's us use them in the context of natural language processing, just to respect accuracy of words. Let us get introduced to some terms. The first one would be a vector. Hold on, lets not get overwhelmed by trigonometry. Let us think that it is a line drawn on a piece of paper, with an X axis and Y axis. Imagine words as vectors. If two words are wide apart, the angle between them is more, if they are close the angle is less. So now we have a concept Word to Vector (Word2Vec). Since Word2Vec is the hottest topic in this domain, there are already some of the prevalent techniques like tf-idf are currently used on a wide scale.
In order to calculate text similarity, typical steps are:
- Representation of text into vector form
- Calculating similarity between two vectors
Some techy definitions
Word2Vec
Word2vec is a group of related models that are used to produce word embeddings. These models are shallow, two-layer neural networks that are trained to reconstruct linguistic contexts of words. Word2vec takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space. Word vectors are positioned in the vector space such that words that share common contexts in the corpus are located in close proximity to one another in the space.
Cosine similarity
Cosine similarity: It is a measure of similarity between two non-zero vectors of an inner product space that measures the cosine of the angle between them. The cosine of 0° is 1, and it is less than 1 for any angle in the interval (0,π] radians.
lemmatization
This relates to getting to the root of the word. For instance the root of determine and decide would come from "de" and a few more terms. So lemmatization is essentially a process of grouping together the inflected forms of a word so they can be analysed as a single item, identified by the word's lemma, or dictionary form
Stop word
Stop word: usually refers to the most common words in a language like 'a' and 'the'. These words are usually meant to be ignored while determining text similarity
Representation of document into vector form
Now we are talking of the whole document, not just a word. Yes it would be group of sentences that are in turn composed of words. How do we represent a document? In order to represent document into vector form, a reference model is needed, some of the popular modelling algorithms are:

Bag of Words (BOW): In this model, a text (such as a sentence or a document) is represented as a bag (multiset) of its words, disregarding grammar and even word order but keeping multiplicity. The core idea is to create a word model that is based on frequency of words in a corpora of a document.
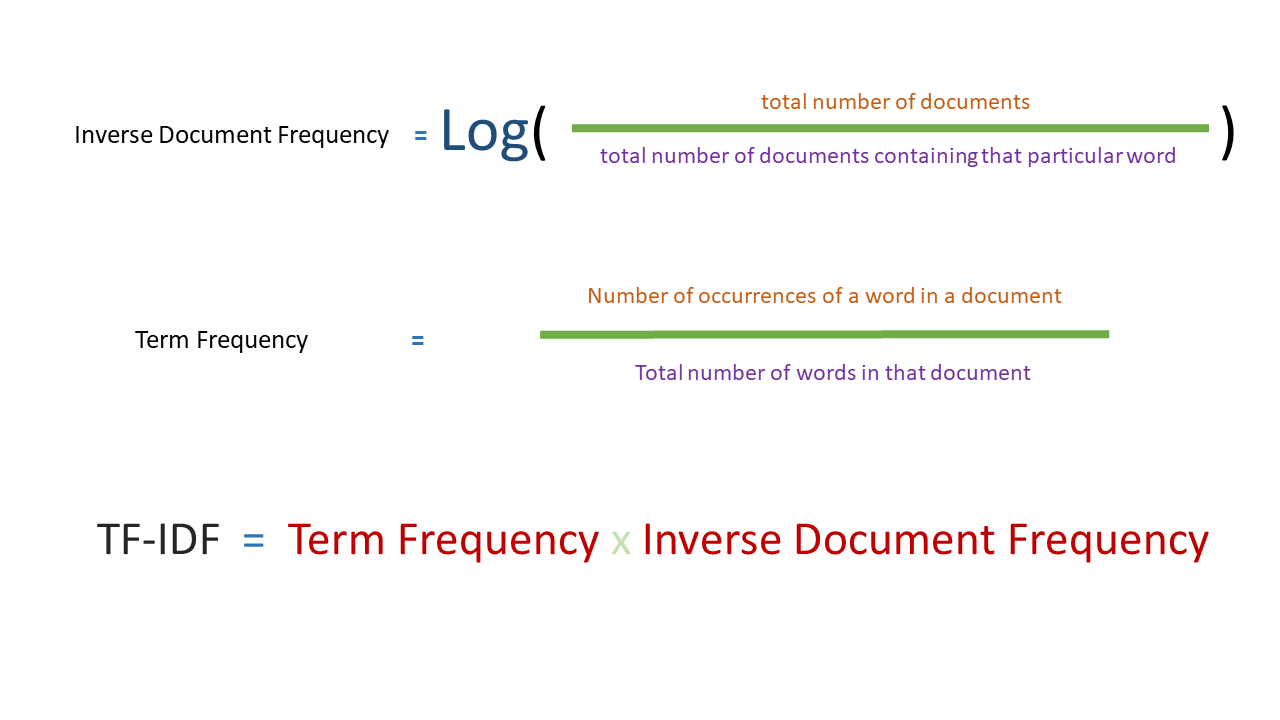
Term Frequency-Inverse Document Frequency (TF-IDF): This is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. It is often used as a weighting factor in searches of information retrieval, text mining, and user modeling. The tf–idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general. Tf–idf is one of the most popular term-weighting schemes today; 83% of text-based recommender systems in digital libraries use tf–idf.
Result: TF-IDF vs Spacy
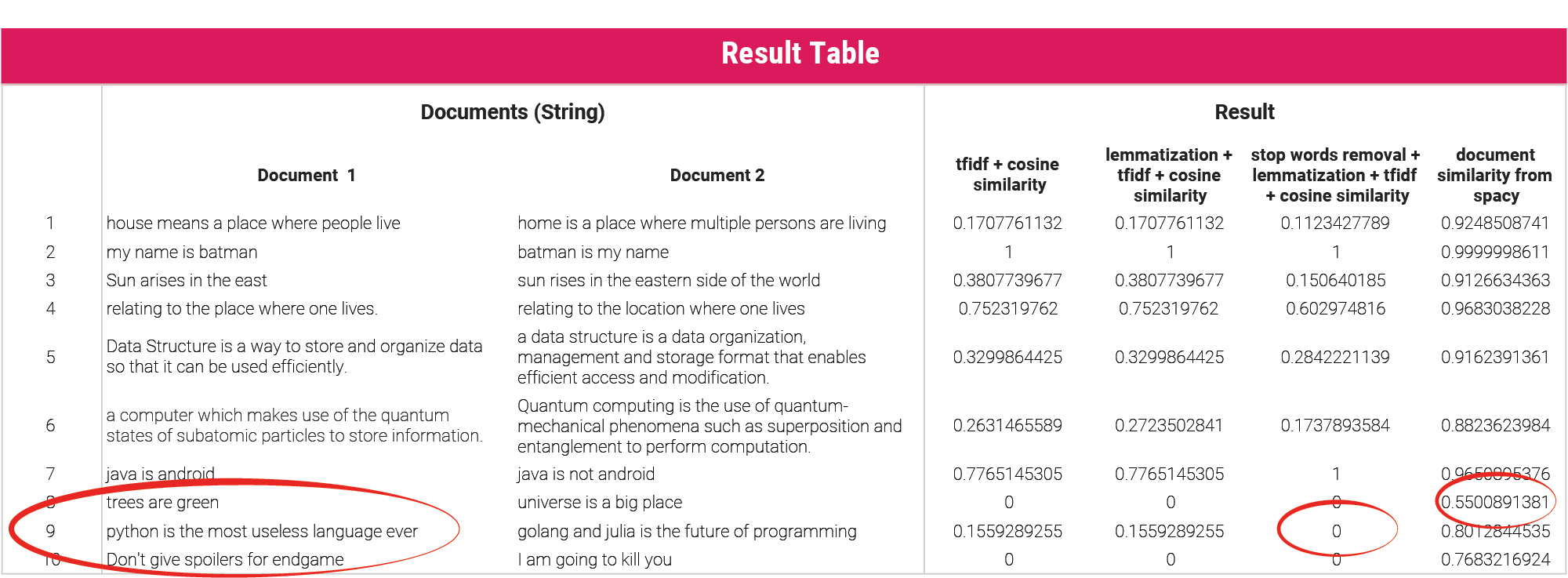
In order to see what results if we computationally want to calculate text similarity, I have used TF-IDF model with variations on preprocessing the text before creating the TF-IDF
Conclusion
Just have a close look at the table. Especially to the sentences 8, 9 and 10. What do you see there. Trees are green and Universe is a big space. What do you think is the similarity in a scale of 0 to 1?
Please do not blame me, yeah you are right, these two are not related. However spacy thinks that there is some similarity.
Consider the line number 9. Python is a programming language - a sure yes. golang and Julia are programming languages as well. And yes there is text similarity. However, the method of stop words removal + lemmatization... gives a brazen ZERO similarity. Not fair right?
So here is what I would conclude, From the result table one can observe that finding cosine similarity after lemmatizing the corpus and then finding TF-IDF gives more intuitive results.
Referred sources: Wikipedia, Spacy documentation