Thinking in documents - dead simple ways to design NOSQL

Data model apt to the usage scenario is now an established way to design databases for application. Relation data model, document oriented data, key-value pair and graph database model can now co-exist in the same application
Now at the beginning of every sprint there is a moment of decision. What is the apt data model for all the entities encountered in the user stories. What is apt for products, what is apt for categories, what about brands, customers, orders, subscriptions, returns, promotions, campaigns and so on. Thankfully there are well defined considerations to shortlist the data model.I was working on an eCommerce project. This is a very ideal candidate to try every damn technology - microservices, microinteractions, digital transformation and AI/ML. This is yet another candidate.
My staple of data models
I'am working for a creative idea by millenials, so the choice got to be in open source databases. The first natural choice is PostgreSQL. Free, proven and mature system. Everything we need is present in it. That was easy. However, relational data model is not the ideal choice for every type of data. In an eCommerce application, every product has varied set of attributes. So the data model got to be NOSQL (Not Only SQL). However i liked to term it is Network Data Model(NDM). In highly distirbuted databases with 100s of microservers for bigdata instead of couple of high power servers, it is really a network of small databases. I intially thought of MongoDB for NOSQL. However soon we bumped upon the requirement of being able to search efficiently using full text search and faceted search, we narrowed down on Elastic. Elastic is an indexed documents model. So really there was no need to have MongoDB and then Elastic. Elastic sufficed my purpose.
Technology fit
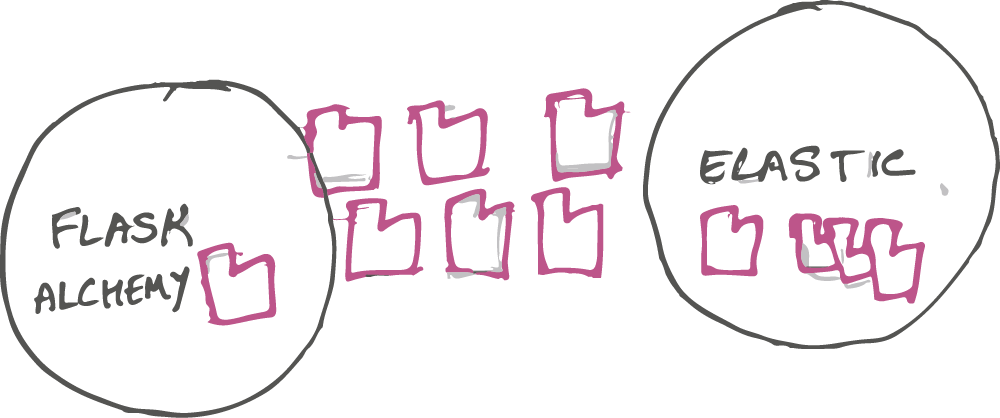
Another popular backend technology today is Python. Am not referring it as a language. Python encompasses all the programming paradigms built into various languages as of today. It is now the most popular dude in all the projects, especially in startups. Python-flask is our application server. Flask has direct drivers for Elastic. So we do not need to connect to Elastic using any endpoint. Usually Elastic exposes endpoints and applications can directly use them. However Elastic is really not designed for developing REST based API.So i rely on Flask for build my endpoints. And then connect to Elastic from my end points using the direct connection from Flask to Elastic.
Criteria to design NOSQL schema
For RDM, we have rules of normalisation to design the database table. We bring it to fifth normal form. But what about NOSQL? What the rules of forming schema. For NOSQL, there are no forms of normalisation. The schema is totally based on our access pattern. There are no negative points for storing data redundantly. Since we are dealing with highly distributed microcomputers, the design considerations are quite different.
What was my design?
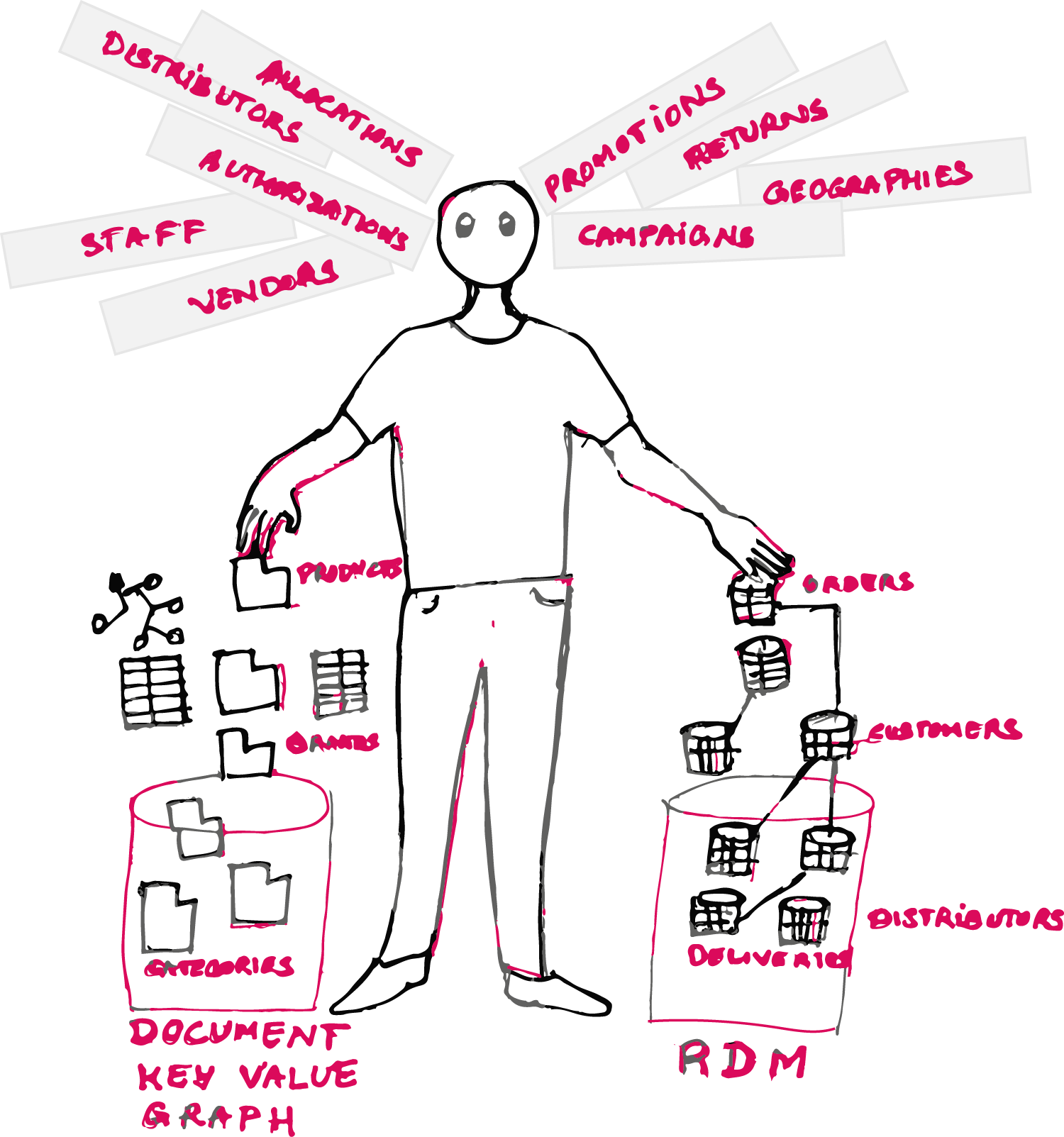
I decided to put all the data that had a fixed structure into our usual relational data model, only the data that had variable structure was designated to go to NOSQL.In my eCommerce project i found three candidates for NOSQL - Products, Brands and Categories. Products that are hosted in such a portal run into thousands. Each with unique set of attributes. Customers can search the products on varied set of attributes. For instance Camera has resolution, Projectors have luminious intensity, Refrigerators has volume and so on. Categories and brands ofcourse do not have varied attributes. However i choose to put them into NOSQL just to keep related entities together. I created 3 documents for these. I store products from a brand within the brands document (Not the whole product, just the product variant model no.), I store within categories all the product variant no., and in the products I again store the brand and list of categories the product variants belong to. So now the data is redundant, however it services my access patterns.
What are my access patterns
My usual route to product variants is either based through search strings like "Laptop", "Camera" and "Microwave oven".
The other access pattern is through faceted search. That is the the search based on the product attributes. For instance, searching laptops based on RAM, searching mobile phones based on camera resolution or searching water filter based on color.
The other pattern is through categories and brands.People can just browse through various products available in categories like smart phones or electrical appliances. More often products, brands and categories are fetched together.
Dealing with documents
Am considering category document to explain various operations like create, edit, delete and search. Am using Python Flask and Elastic database. There is a direct connection from Flask to Elastic. So there is no need to expose API in Elastic. Here is the sample code for various operations.
Define new category
# This is new category
new_category = {
"id": 5,
"child_category": [],
"category_name": "A4",
"status": "Active"
}
Edit a category
def update_category(self, category_name, new_category):
# finding the exist document by category_name
res = es.search(index=ElasticVariable.category_index,
doc_type=ElasticVariable.category_doc_type, body={
'query': {'query_string': {'query': category_name}}})
category_result = res['hits']['hits'][0]['_source'] # calling
python method to append the new category
list(Category.category_return('category_name', category_result,
category_name, new_category)) # updating the document
es.update(index=ElasticVariable.category_index,
doc_type=ElasticVariable.category_doc_type, id=res['hits']['hits'][0]
['_id'],
body={"doc": category_result})
return category_result
Search categories
def category_return(key, value, name, new_category):
# Iterating the doc by key and value
for k, v in value.items():
if k == key:
if v == name:
category = value['child_category']
category.append(new_category)
yield value
elif isinstance(v, dict):
for result in Category.category_return(key, v,
name,new_category):
yield result
elif isinstance(v, list):
for d in v:
for result in Category.category_return(key, d, name,
new_category):
yield result
Conclusion
NOSQL requires a very different type of approach to store and access data. It requires a perspective of a highly distributed database. It needs to be viewed in the context of Bigdata. Not just that, there are other considerations like pagination in the front end while retrieving joining and merging with data in relational data models. However, it is for sure fast and an essential requirement especially in the context of Microservices.